
[BA] MySQL로 트래픽 소스 트렌딩(traffic source trending) 분석하기
✔ ‘bid optimization’은 어떤 개념인가?
: 먼저 ‘bid’가 어떤 맥락에서 사용되고 있는지부터 보자. 사전적 의미는 ‘입찰’, ‘유치’, ‘값을 매기다’ 와 같다. 그렇다면 디지털 마케팅 상에서는 어떤 상황을 표현하는 걸까?
웹 사이트에 방문하거나 앱을 사용하면 ‘display advertisement(웹사이트나 앱 화면 내에 보이는 광고)’를 쉽게 발견할 수 있다. 이 화면 영역 내에서 광고가 고정적이지 않고 페이지가 전환될 때마다 바뀌는 걸 본 적이 있을 것이다. 광고를 띄우려면 광고비(자릿값)를 지불해야 하는데, 이게 ‘bidding’ 형태로 이루어진다. 다시 말하면, 여러 광고주가 참여한 옥션(경매)이 시작되고 가장 높은 가격을 제시하는 광고주의 광고가 해당 영역을 차지하는 것이다.
광고주 입장에서 높은 가격을 제시해 자리를 얻은 만큼 원하는 ‘결과’를 얻길 바랄 것이다. 하지만 지불한 광고비에 상응하게 원하는 결과(클릭률, 위치, 노출 정도 등)를 갖는 것은 쉽지 않다. 그렇게 만드는 다양한 외부적 요인이 있는데, 다음과 같다.
- 다른 경쟁 광고주들의 경매가, 예산, 키워드, 고객층, 창의적인 광고 등의 변화는 옥션에 상당한 영향을 미친다.
- 시간의 변화, 겨울이면 따뜻한 옷을 구입하는 게 증가하는 것처럼 매 시간, 매 주 계속해서 다양한 변화가 계속 일어난다.
- 사건, 사고 그리고 유행은 큰 변화를 만든다. 예를 들어 SNS에서의 유행하는 물건이나 상황 등은 갑작스런 소비 혹은 구매로 이어진다. 그리고 이건 예측할 수 없다.
- 광고 플랫폼은 ‘질’이나 ‘퍼포먼스’ 등 다양한 요인을 기준으로 ‘옥션’을 진행하고 수정할 수 있다.
이러한 요인들로 인해 광고주가 ‘같은 경매가(bidding price)’를 매 옥션마다 제시하는 건 좋은 선택이 될 수 없다. 따라서 디지털 마케팅 캠페인을 진행하는 데 'bidding price optimization'은 중요한 접근 혹은 수단이 될 수 밖에 없는 것이다. 적절한 광고 경매 비용을 산정하기 위해 지표를 다시 평가하고, 계산하고, 갱신하며 ‘경매 비용 최적화(bidding price optimization)’를 하는 것이다.
✔ ‘bid optimization’을 위해 무엇을, 어떻게 분석할까?
: 유료 트래픽의 여러 세그먼트 값을 파악해 디지털 마케팅 비용을 최적화하려고 한다. 얼마의 수익을 내고 있는지에 따라 유료 트래픽 세그먼트들에 적합한 ‘bid price’를 부여할지 알아보고자 한다.
예를 들어, 세그먼트 A, 세그먼트 B, 세그먼트 C가 있다고 하자. 각각의 CVR(Conversion Rate)가 10%, 3%, 17% 라고 할 때, 세그먼트 B는 다른 두개에 비해 CVR이 매우 낮다. 이런 상황일 때 세그먼트 B의 비용을 줄이고, 세그먼트 A와 세그먼트 C에 비용을 늘리는 것을 고려해 볼 수 있다.
✔ DATE Function에 대해 짚고 가기
- YEAR(): ‘date’ 혹은 ‘datetime’ 데이터로부터 ‘년’에 해당하는 부분을 추출하는 함수
- QUARTER(): ‘date’ 혹은 ‘datetime’ 데이터로부터 ‘분기(4분기 기준)’에 해당하는 부분을 추출하는 함수
- MONTH(): ‘date’ 혹은 ‘datetime’ 데이터로부터 ‘월’에 해당하는 부분을 추출하는 함수
- WEEK(): ‘date’ 혹은 ‘datetime’ 데이터로부터 ‘주’에 해당하는 부분을 추출하는 함수
- DATE(): ‘date’ 혹은 ‘datetime’ 데이터로부터 ‘일’에 해당하는 부분을 추출하는 함수
- NOW(): 현재에 해당하는 시간을 계산
💡 TIP: date function을 GROUP BY 혹은 집계 함수 COUNT(), SUM() 등과 같이 쓰면 트렌드(시간의 흐름에 따른 변화)를 파악하기 용이하다.
** DATE Function 쿼리 예제 - Year, Week를 기준으로 세션 접속 카운팅하기(중복 세션 제외)
SELECT
YEAR(created_at) AS by_year,
WEEK(created_at) AS by_week,
MIN(DATE(created_at)) AS week_start, -- 'by_week'를 기준으로 가장 최소값 데이트 ==> 주가 시작되는 date 출력
COUNT(DISTINCT website_session_id) AS sessions -- 중복 제외 website_session_id 카운트
FROM website_sessions
WHERE where created_at between '2013-08-01' and '2015-03-02' -- 랜덤으로 기간 설정
GROUP BY 1, 2 -- Year, Week로 그룹핑
ORDER BY 1 -- Year를 기준으로 올림차순
;
✔ 어떤 요청이 들어올 수 있을까?
현재 상황: 이전 분석으로
source='gsearch' & utm_campaign = 'nonbrand'세션의 구입 전환율은 약 3%인 것으로 파악되었다. 이는 기준 4%를 넘지 못하였으므로 비용을 감축하기로 하였고, ‘2012-04-15’ 일자를 기준으로 해당 세션에 bidding down이 진행되었다.
A. 비용 감축 이후 ‘gsearch nonbrand’ 세션의 볼륨(volume)을 주 간격으로 어떻게 변화하였는지 파악하고 싶습니다. (2012년 5월 10일 기준)
B. 저희 서비스 사이트를 모바일로 이용하는 데 불편한 감이 있었습니다. 장비 별 차이가 있을 것으로 예상되는데, 'gsearch nonbrand' 세션의 장비 별 세션 수, 주문 수, 그리고 구입 전환율(CVR)이 어떻게 되는지 궁금합니다. 장비 별 차이가 있으면 비용을 달리할 예정입니다. (2012년 5월 11일 기준)
C. ‘2012-05-19’ 일을 기준으로 ‘gsearch nonbrand’ 세션의 데스크탑용 마케팅 비용을 늘렸습니다. ‘2012-04-15’ 이후의 주간 장비 별 세션 볼륨(volume)이 어떻게 변화했는지 파악하고 싶습니다. (2012년 6월 9일 기준)
✔ 어떻게 SQL 쿼리를 작성할까?
A. website_session_id를 중복제외 카운팅을 하는데, ‘주’를 단위로 group by
SELECT
MIN(DATE(created_at)) as week_start_date,
COUNT(DISTINCT website_session_id) as sessions
FROM website_sessions
WHERE created_at < '2012-05-10' -- 2012-05-10을 기준으로 제한
AND utm_source = 'gsearch' -- gsearch nonbrand 세션 값만 고려
AND utm_campaign = 'nonbrand'
GROUP BY WEEK(created_at)
🔔 GROUP BY를 WEEK(created_at)과 created_at으로 하는 데 어떤 차이가 있을까?
보통 ‘created_at’은 해당 내용이 생성되는 그 시간인 ‘timestamp’인 경우이기 때문에 primary key 못지 않게 해당 row의 고유성을 갖고 있는 데이터 컬럼이다. 그렇다면 이 컬럼으로 GROUP BY를 진행하면 중복되는 값이 없기 때문에 'sessions' 컬럼 값이 1이 되어버린다. 처음에 이 부분을 고려하지 못해 원하는 결과값을 얻지 못했다. 어떻게 ‘주’ 간격의 세션 수를 얻을 수 있을지 고민해 ‘WEEK(created_at)’으로 그룹핑을 진행했다. 그 결과로 ‘week_start_date’ 컬럼은 매주의 가장 최소값(가장 빠른 날)이 들어오고 ‘sessions’ 컬럼에는 매주의 세션 수가 값으로 들어왔다.
🔔 SQL을 진행하면서 간과하기 쉬운점 ==> GROUP BY는 SELECT 되지 않은 구문이라도 진행할 수 있다.
💡 결과 해석하기
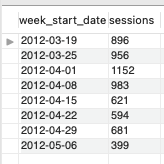 ** ‘2012-04-15’를 기준으로 ‘gsearch nonbrand’ 세션에서 광고 비용을 감출하였고, 쿼리 결과로도 확인되듯이 이 날을 기준으로 ‘sessions’ 수가 600대로 줄어든 것을 확인할 수 있다.
** ‘2012-04-15’를 기준으로 ‘gsearch nonbrand’ 세션에서 광고 비용을 감출하였고, 쿼리 결과로도 확인되듯이 이 날을 기준으로 ‘sessions’ 수가 600대로 줄어든 것을 확인할 수 있다.
** 해당 세션은 비용 변화에 민감하게 반응하지만, 전환율이 낮기 때문에 비용을 더 늘릴 수는 계획이 없으므로 이전의 볼륨은 유지하면서 비용은 유지할 수 있을지를 고민해볼 필요가 있다.
B. device type 별 sessions, orders, conversion rate 구하기
SELECT
website_sessions.device_type,
COUNT(DISTINCT website_sessions.website_session_id) AS sessions,
COUNT(DISTINCT orders.order_id) AS orders,
COUNT(DISTINCT orders.order_id) AS orders / COUNT(DISTINCT website_sessions.website_session_id) AS conv_rt
FROM website_sessions
LEFT JOIN orders
ON website_sessions.website_session_id = orders.website_session_id
WHERE website_sessions.created_at < '2012-05-11'
AND utm_source = 'gsearch'
AND utm_campaign = 'nonbrand'
GROUP BY 1
💡 결과 해석하기
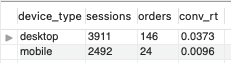
- 장비 별 전환율 값이 크게 차이가 나는 것으로 드러났다. 모바일 구입 전환율은 1%도 되지 않으나 데스크탑은 4%에 가까운 전환율을 보이고 있다. 데스크탑 마케팅 광고 비용을 늘리고 해당 트래픽에서 판매를 촉진하는 방향으로 추진해야 한다.
- 추가적으로 이용자가 모바일을 이용하는 데 불편한 부분이 있다면, 기획 혹은 개발 부서에 요청해 기존 ui/ux의 수정 작업을 진행할 필요가 있다. 이를 통해 모바일 서비스 유저의 편리성 혹은 접근성을 높여야 한다.
C. traffic source segment trending analysis ==> 장비 세그먼트 세션 수 파악
-- pivoting with case when statements
SELECT
MIN(DATE(created_at)) AS week_start_date,
COUNT(DISTINCT CASE WHEN device_type = 'desktop' THEN website_session_id ELSE NULL END) AS dtop_sessions,
-- device_type이 'desktop'이면 website_session_id를 값으로 두고 distinct count 하겠다 ==> 데스크탑에서의 세션 수
COUNT(DISTINCT CASE WHEN device_type = 'mobile' THEN website_session_id ELSE NULL END) AS mob_sessions,
-- device_type이 'mobile'이면 website_session_id를 값으로 두고 distinct count 하겠다 ==> 모바일에서의 세션 수
COUNT(DISTINCT website_session_id) AS total_sessions
FROM website_sessions
WHERE created_at < '2012-06-09'
AND created_at >= '2012-04-15'
AND utm_source = 'gsearch'
AND utm_campaign = 'nonbrand'
GROUP BY WEEK(created_at)
🔔 case when 구문에서 then 이후에 ‘website_session_id’로 정한 이유는 고유값이므로 세션 수마다 카운팅이 되기 때문이다. 따라서 ‘created_at’을 주어도 같은 결과를 얻을 수 있다.
💡 결과 해석하기
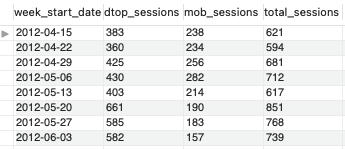
- ‘2012-05-19’일을 기준으로 데스크탑 트래픽에 마케팅 비용을 늘렸고, 결과적으로도 그 다음부터 데스크탑 세션 수가 확연하게 늘어난 것을 확인해 볼 수 있다. 또한 모바일 트래픽은 비용을 줄였고, 그 전과 크게 다르지 않거나 세션 수가 약간 더 떨어진 것으로 나타났다.
- 이를 통해 디지털 마케팅의 비용 차이가 장비 별로도 드러났으며, 유저들에게 노출이 되면 될수록 세션 유입량도 늘어난다는 것을 추측해볼 수 있다. 이 상관관계를 어떻게 더 효율적으로 활용할 수 있을지 고민해 볼 필요가 있다.
✔ 무엇을 남겼나
- 가장 큰 것은 디지털 마케팅이 어떠한 것인지에 대한 이해와 광고비 운영 ‘최적화’가 비즈니스에서 매우 중요하다는 점을 배웠다. 그렇기에 더욱 데이터를 잘 다루고 ‘어떤 새로운 관점과 방식으로 인사이트를 찾아내는 것’ 역시 중요한 역량일 수 있겠다는 것을 느꼈다.
- 데이터 분석으로 지원해서 떨어진 적이 있었는데, 비즈니스적 경험이 부족하다는 피드백을 받았다. 물론 납득할 만한 이유였지만 그 ‘비즈니스’라는 도메인을 아는 게 왜 그렇게 중요한 걸까라는 의문이 있었는데, 지금 과제를 진행하면서 내가 알지 못했던 다양한 방식과 접근, 개념이 있고 이것을 잘 활용할수록 비즈니스 운영이 용이하다는 것을 느끼면서 나의 부족한 점을 더욱 채워야 겠다는 것을 배웠다.
- 또한 SQL로 간단한 pivoting 예문을 진행하면서 다시금 적용 원리를 이해할 수 있어 매우 유익한 시간이었다.
댓글남기기